سیستم های نرم افزاری بزرگ شامل چندین میلیون خط از کد و مجموعه ی عظیم مستندات هستند. آنها از ترکیب اجزاء متعدد نرم افزاری و کد های واسط این اجزاء به وجوده آمده اند. این فرآیند (ترکیب اجزای گسسته نرم افزاری) فقط زمانی قابل اعتماد است که رفتار کد های واسط و اجزاء مرکبی که سیستم از یکپارچگی آنها حاصل شده به درستی درک شود.
«جزئیات چنین طراحی عظیمی نباید و نمی تواند تنها توسط یک نفر درک شود.» Curtis این سناریو را به عنوان پیچیدگی روانی (psychological complexity ) معرفی می کند. Basili اما پیچیدگی نرم افزاری را «اندازه گیری منابع مصرفی توسط سیستم در زمان تعامل آن با بخشی از نرم افزار» تعریف می کند. در تعریف اخیر اگر منظور از «تعامل سیستم» یک کامپیوتر باشد ، پیچیدگی عبارت است از فضای مورد استفاده و زمان اجرا. اگر منظور از «تعامل سیستم» یک برنامه نویس است پیچیدگی عبارت از انجام عملیاتی مانند توسعه ، دیباگ ، تست و ویرایش کد آن خواهد بود. اصطلاح پیچیدگی نرم افزار (Software Complexity) معمولا به تعامل بین برنامه و برنامه نویس طی فرایند های مختلف توسعه (تست – دیباگ – توسعه ..) اشاره دارد. (برای برسی فضا و زمان اجرا واژه ی software performance رایج تر است.)
هر دو نویسنده در مکتوبات خود بر این مطلب تاکید داشته اند که استفاده از تکنیک های توسعه ساخت یافته (structured programming techniques ) دشواری درک کد ها را برای مهندسان نرم افزار چند برابر کرده است. گستردگی کد های این روزها تصور استفاده از ساختار های غیر ساخت یافته را تقریبا غیرممکن می سازد. حتی بیش از آن ادراکات انتزاعی طراحان کامپایلر/مفسر در ارائه ی راهکار هایی نوین چاره ای جز هماهنگی با تکنیک های توسعه باقی نخواهد گذاشت. کلاس ها – تمپلیت ها و مفاهیم انتزاعی دیگر که در صورت استفاده در یک سیستم نرم افزاری ، مراتب درک را دشوار تر می سازد اما عملکرد را بهبود می بخشد و امکان پیاده سازی و توسعه پذیری ساختار های پیچیده را میسر می دارد ، امروز جزء جدانشدنی توسعه هستند . متاسفانه نه برنامه نویسی ساخت یافته و نه تکنیک های توسعه امروزی از نگرانی های مرتبط با پیچیدگی نرم افزار نمی کاهد.
نرم افزار شما تا چه حد پیچیده است؟
٪۱ از پیچیده ترین ساب روتین های سیستم شما کجاست؟
سیاست نگهداری از آن ۱٪ چیست و چرا؟
قبل از اینکه بدانیم چرا پاسخ این سوالات مهم است لازم است بدانیم مزیت اطلاع از سطح پیچیدگی سیستم چیست؟
این دانش:
- اولا قابلیت پیشبینی شما را در مدیریت پروژه های نرم افزاری افزایش می دهد. اطلاع از «سطح پیچیدگی نرم افزار » (Software Complexity) و میزان درگیری با این بخش از کد کمک شایانی در برآورد زمان نگهداری یا توسعه ی بخش های مختلف و مرتبط با این بخش خواهد بود.
- با کنترل و مدیریت بخش های پیچیده ، ریسک آسیب پذیری و نقص کاهش یافته و پتانسیل بروز خطا به طور محسوسی کنترل خواهد شد.
- کاهش هزینه ی نگهداری نرم افزار با پرهیز هوشمندانه از درگیری با بخش های پیچیده و یا افزودن به پیچیدگی غیر ضروری از دیگر مزایای این اطلاع است.
- می توانید با پرهیز از پیچیدگی بی حد و غیر ضروری ارزش و عمر مفید نرم افزار را افزایش دهید.
- می توانید ارزیابی دقیق تری از اینکه « چه زمانی به بازنویسی کد نیاز است» نسبت به اینکه« چه زمانی به نگهداری کد نیاز است» در دست داشته باشید.
چرا ارزیابی سطح پیچیدگی برای سیستم های بزرگ مهم است؟
نقل قولی از پروفسور Alain April در دست است که :
«نگهداری از یک نرم افزار مستلزم تنزل رتبه عملکردی آن است.»
احتمالا شما هم در نگاه اول شگفت زده می شوید چرا که تصور عمومی و رایج این است که نگهداری از سیستم کارایی را بهبود می بخشد!!! مایه تعجب است اما سرانجام شما هم از صحت آن مطلع می شوید. (به شخصه یکی از عواملی که مرا از استفاده ی متد های Agile در پروژه های بزرگ هراسان می کنه همین موضوع است. از نظر من Agile مثلSpiral یا Waterfall پتانسیل پیشبینی و تخمین دقیق ندارد و این موضوع عامل پیچیدگی ناخواسته خواهد شد. وقتی که تصورات شما از عملکرد بخش هایی از سیستم حین تعامل با مشتری به وجود میاد یا حتی ناشی از Roadmap با تحلیل ضعیف باشد شما توانایی کمتری در انتخاب متد دارید. این پیچدگی های ناخواسته زمان نگهداری واقعا مایه زحمت هستند . کد های عجیب ناشی از عدم پیشبینی ، پروژه را ناپایدار خواهند کرد. اگرچه در بدو شروع پروژه ، سیستم ظاهرا عملکرد خوبی دارد – اما در اولین فاز نگهداری و توسعه پیچیدگی ها بروز می کند. شاید شما هم بعضا تعجب کرده باشید و از خود بپرسید «این کد چرا کار می کند!!!» این ماجرا جای بحث مفصل دارد و نیاز به مشاوره مدیران پروژه با سوابق طولانی در پروژه های بزرگ...)
همچنین پروفسور Meir Lehman در تدوین «هشت قانون تکامل و توسعه نرم افزار » - در بند دوم اشاره می کند که :
«وقتی یک سیستم تکامل می یابد ، سطح پیچیدگی آن نیز رشد می کند مگر آنکه تدابیری برای کاهش پیچیدگی اتخاذ شود.»
محقق پیشرو در حوزه دانش سنجش نرم افزار Capers Jones اشاره می کند که بیشتر توسعه دهنده گان پیش از آنکه با توسعه یک بخش جدید مرتبط باشند ، به طور مستقیم با نگهداری یک سیستم درگیر اند :
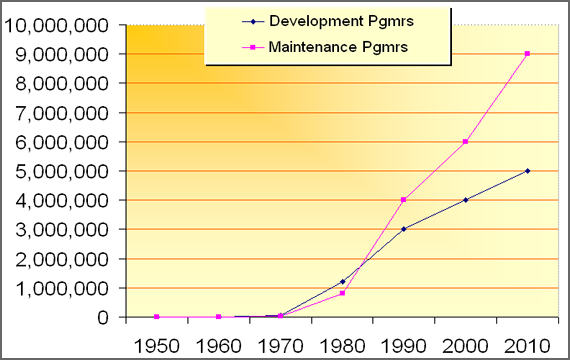
ضمن اینکه توجه داشته باشید که همواره خواندن و دیباگ کد از نوشتن آن دشوار تر است. در این مورد نیز نقل قول محبوب من از Brian Kernighan :
« همه می دانند که debuging دو برابر دشوار تر از نوشتن یک کد برای نخستین بار است. پس اگر شما به اندازه ای باهوش هستید که در زمان نوشتن آن کد بوده اید ، چگونه می توانید آن را دیباگ کنید!؟»
شاید این مطلب هم به اندازه ی مطالب بالا شگفت آور باشد. توسعه دهنده گانی که از یک سیستم نگهداری می کنند ، تحت فشار مهیب برای نگهداری نرم افزارهایی هستند که با تجربیات بعضا بیش از یک دهه گذشته تنظیم و نوشته شده اند و سطح پیچیدگی آنها به شدت متغییر و متاثر از تکنولوژی آن زمان بوده است. ضمن این که غالبا درگیر کدهایی هستند که خود نقشی در تحلیل ، توسعه و پیاده سازی آن نداشته اند و باید بر مبنای دو اصل سرعت و کیفیت ، بخوانند - درک کنند و توسعه دهند پس تصور اینکه این نگهداری بر پیچیدگی سیستم کم اثر باشد امری دور از ذهن است.
سنجش و اندازه گیری پیچیدگی
برای ما جامعه ی مهندسین چیزی که قابل اندازه گیری نباشد نسبی است و امور نسبی با قاطعیت قابل اظهار نظر نیستند. پس می توان نتیجه گرفت که ما نمی توانیم چیزی را که قادر به اندازه گیری آن نیستیم به طور موثر مدیریت کنیم. بنابر این اولین چیزی که نیاز به تمرکز دارد ، چگونگی سنجش پیچیدگی نرم افزار است. متد های متعددی برای سنجش پیچیدگی نرم افزار تدوین شده است که اکثرا مستقل از زبان و گستردگی سیستمها هستند این متند ها حتی در یک زبان مفسری مانند PHP که زبان مورد نظر ما در ارائه ی این بحث است ، قابل اعمال اند.
اساس کلیه متد های ارائه شده ، ظرفیت ها و محدودیت های ذهن انسان در تقابل با پردازش کامپیوتری است و اینکه ذهن انسان به سختی می تواند تسلسل پردازش را مانند آنچه که در کامپیوتر ها دنبال می شود حفظ کند.
برای درک و توسعه نرم افزاری که نیاز به نگهداری و توسعه دارد ، ابتدا محققان علوم شناختی و تحلیلی ، روند درک ذهنی توسعه دهنده گان را به چندین وظیفه ی سطح بالا می شکنند : مثلا درک جریان کنترل نرم افزار (program’s control flow) و درک گردش داده ی نرم افزار (program’s data flow).
آیا می توانیم با برسی کد یک نرم افزار به برآورد اینکه درک جریان کنترل و نیز درک گردش داده ی نرم افزار تا چه حد برای یک برنامه نویس پیچیده است برسیم؟؟؟؟ پرسش بسیار مهمی است. در واقع چند تئوری بدین منظور موجود است:
Cyclomatic complexity یا McCabe measures
معیار سنجش میزان جریان کنترلی در برنامه است که به سال ۱۹۷۶ توسط Thomas J. McCabe معرفی شد و پرکاربرد ترین معیار منطقی است. در تئوری ، این معیار به کمک گراف کنترل گردش (control flow graph) برسی می شود. در PHP عبارات کنترل جریان شامل : if , while , do , for , foreach , declare, return , require , include , goto می باشند. همه ی ما می دانیم که یک برنامه با منطق شرطی بیشتر ، برای درک دشوار تر است و این سبک سنجش یک ارزیابی از این موضوع در اختیار قرار می دهد. این معیار تعداد مسیر های گردش خطی یک برنامه را اندازه می گیرد. برای مثال در یک تابع که هیچ عبارت شرطی وجود ندارد تنها یک مسیر موجود است.
دشواری درک با افزایش راه های خروج یک قطعه برنامه نیز افزایش می یابد. معیار McCabe را به سادگی می توان تعریف کرد:
M = E - N + 2P
(M=McCabe Cyclomatic Complexity (MCC
E=تعداد یال ها
N=تعداد نود ها
p= اجزاء مرتبط
در ادبیات رایج برنامه نویسان ، یال ها ناشی از یک تصمیم و اجزاء مرتبط شامل هر فراخوانی یا خروج صریح است. همچنین MCC برای تعیین قابلیت تست نرم افزار نیز مورد استفاده قرار می گیرد. مقدار بیشتر برابر است با دشواری و ریسک بیشتر برای تست و نگهداری سیستم. مقادیر استاندارد از Cyclomatic Complexity در جدول زیر به نمایش گذاشته شده است.
| میزان ریسک |
Cyclomatic Complexity |
| برنامه ساده – بدون ریسک موثر |
1-10 |
| برنامه نسبتا پیچیده – ریسک محدود |
11-20 |
| برنامه پیچیده – ریسک بالا |
21-50 |
| برنامه غیر قابل اعتماد – ریسک بسیار بالا |
51+ |

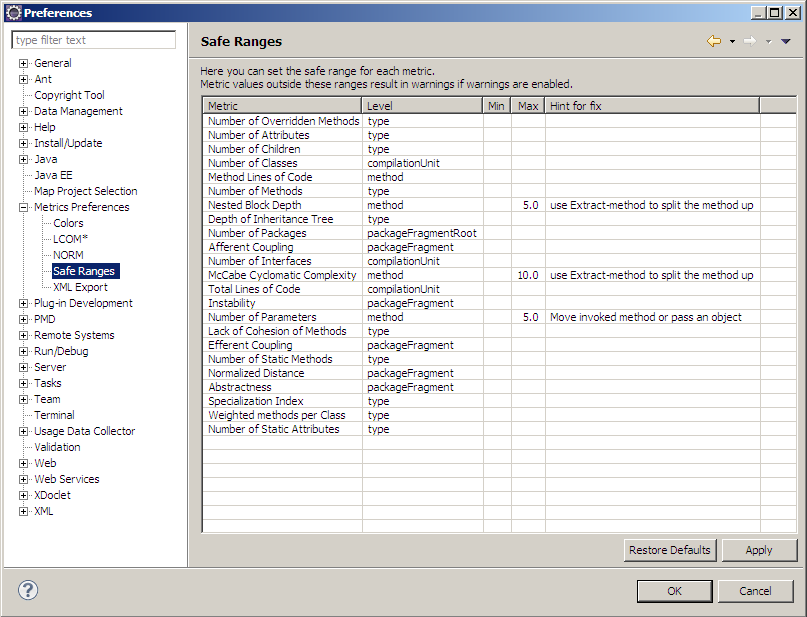
برای نمونه گراف مقابل یک نمودار جریان کنترل ساده است. برنامه از نود قرمز شروع و با ورود یه یک حلقه (شامل گروهی از ۳ نود ) ادامه می یابد. پس از خروج از حلقه یک عبارت شرطی برقرار است و سر انجام در نقطه آبی برنامه پایان می پذیرد. این گراف متشکل از ۹ یال ، ۸ نود و ۱ جزء متصل (ورود و خروج صریح) می باشد که رابطه MCC آن عبارت است از: MCC= 9 – 8 +2*1=3; مطابق جدول استاندارد مشروح این برنامه« بدون ریسک موثر» است. ابزار های متعددی به منظور استفاده از این معیار ارائه شده است که یکی از جذاب ترین آنها (نظر شخصی) Eclipse Metrics plugin است. (بعدا مفصلا در باب مقایسه Eclipse و Netbeans و VS خواهم نوشت !!!!…)
این پلاگین امکان اعمال محدودیت جهت کاهش سطح پیچیدگی جریان کنترلی را به دست می دهد. از جمله محدودیت در دفعات Overridden (در PHP به شکل نرمال نداریم) – تعداد کلاس ها – تعداد فرزندان – عمق درخت وراثت و مسئله مورد نظر ما کنترل MCC…. برای اطلاعات بیشتر : (http://metrics2.sourceforge.net)
(Source lines of code (SLOC
یک مقیاس سنجش اندازه یک نرم افزار به کمک شمارش خطوط کد آن است که حجم کار صورت گرفته را نشان و همچنین به عنوان شاخص برآورد میزان بهره وری حین پروسه ی نگهداری نیز شناخته می شود. در این مورد شاید مطالعه پروژه های بزرگ عصر ما خالی از لطف نباشد.
https://docs.google.com/spreadsheet/ccc?key=0Aqe2P9sYhZ2ndElxbjVTcnV2bHFOWmUwSkt2bjZLdVE&usp=drive_web#gid=5
این اطلاعات در یک قالب گرافیکی به همت پایگاه http://www.informationisbeautiful.net به صورت زیر قابل برسی است.
http://www.informationisbeautiful.net/visualizations/million-lines-of-code
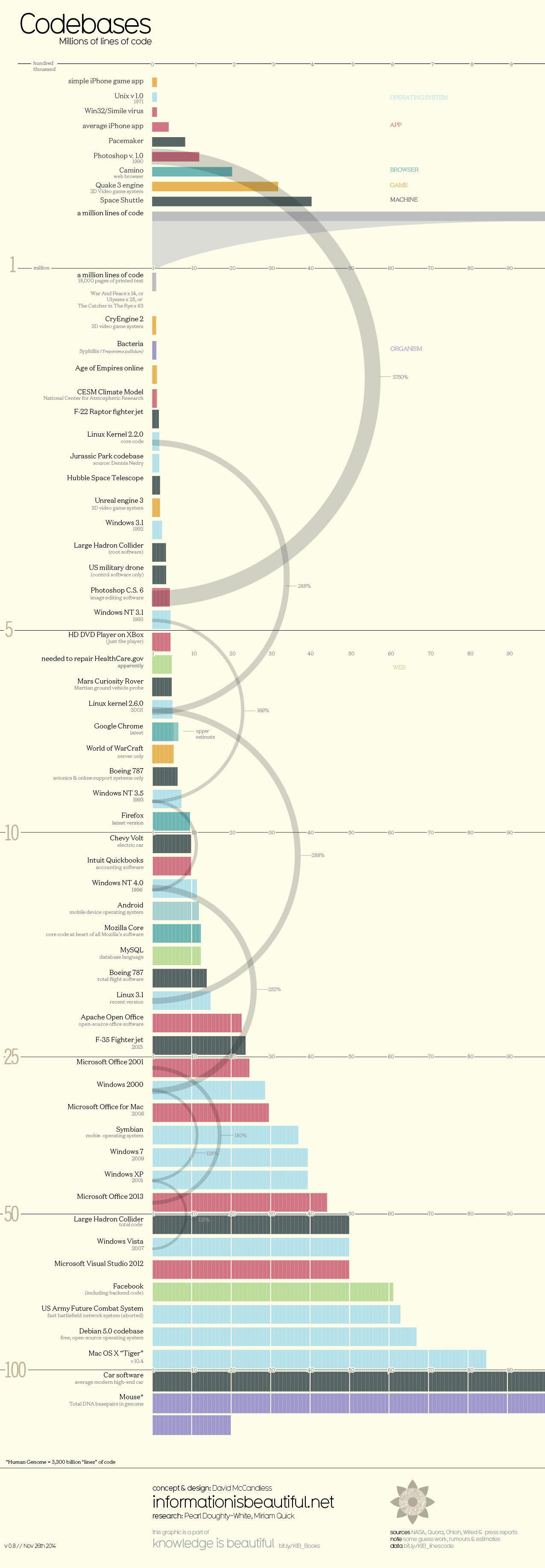
یک نکته دیگر در این مورد تعداد خطوط کد های کامنت شده است. توضیحاتی که برای درک بهتر برنامه نویس ارائه می شود طبعا کمک شایانی در درک زودتر و نیز کاستن از سطح پیچیدگی ارائه می دهند.
Halstead volume
سطح هالستد یک مقیاس سنجش نرم افزار است که توسط Maurice Howard Halstead به سال ۱۹۷۷ برای سنجش سطح داده در سورس کد ، که برای کشف و درک بهتر از جریان داده باید مورد مطالعه قرار گیرد مطرح شد (در واقع ساختمان داده های مورد استفاده). این مقیاس سنجش ، بر روی اینکه چه تعداد متغییر تعریف شده و نرخ کثرت و قلت مراجعه به آنها چگونه است مطالعه می کند. همچنین همین مطالعه در سطح توابع و کلاس ها و نیز تکه کد های اضافی حاوی داده نیز بطور موثر انجام می شود. به طور خلاصه این مقیاس برای سنجش درجه و نرخ داده های موثر در کد مورد استفاده است.
Maintainability index
بحث ما در مورد جامعه مهندسی و ارزش اندازه گیری در این شاخص سنجش نمود بیشتری خواهد داشت. شاخص قابلیت نگهداری تلاش می کند تا به کمک شاخص های دیگری چون lines-of-code measures, McCabe measures و نیز Halstead complexity به یک فرمول واحد برای استخراج نمره چگونگی نگهداری برسد. این مقیاس سنجش و عناصر دخیل در آن نقش موثر و مشهودی در کاهش استعداد نرم افزار در بی نظمی در کد و کاهش یکپارچگی آن همچنین کاهش هزنیه ها و نیز کاهش ریسک بازنویسی بخشهای متعدد خواهد داشت.
به عنوان یک جمع بندی پیچیدگی یک نرم افزار به سادگی برسی عملکرد آن نیست. لزوما از اینکه یک نرم افزار یا حتی یک تکه کد چه کاری انجام می دهد نمی توان پیچیدگی آن را تخمین زد. پیشبینی پیچیدگی یک نرم افزار عوامل متعددی را شامل می شود و اطلاع از آن نیز بسیار ضروری است. لازم است که شما پیچیده ترین اعضای سیستم تان را بشناسید و از سطح پیچیدگی آن مطلع باشید تا اگر این بخش از کد در یک فرآیند توسعه یا نگهداری دخیل شد ، بتوانید تصمیمات موثر اتخاذ کنید.
: References
V.S. Alagar, K. Periyasamy - Specification of Software Systems (Book)
Joseph K. Kearney, Robert L. Sedlmeyer, William B. Thompson, Michael a. Gray, and Michael A. Adler - software complexity measurement - http://www.lsmod.de/~bernhard/cvs/text/dipl/dipl/papers/kearney.pdf
http://en.wikipedia.org/wiki/Software_metric
http://en.wikipedia.org/wiki/Cyclomatic_complexity
http://en.wikipedia.org/wiki/Maintainability
http://en.wikipedia.org/wiki/Source_lines_of_code
http://en.wikipedia.org/wiki/Halstead_complexity_measures
http://php.net/manual/en/language.control-structures.php
http://www.databorough.com
http://www.linuxjournal.com/article/8035?page=0,0
https://docs.google.com/spreadsheet/ccc?key=0Aqe2P9sYhZ2ndElxbjVTcnV2bHFOWmUwSkt2bjZLdVE&usp=drive_web#gid=5 http://www.informationisbeautiful.net/visualizations/million-lines-of-code/
